Scaling User Modeling: Large-scale Online User Representations for Ads Personalization in Meta
0 ABSTRACT
有效的用户表示在个性化广告中至关重要。然而,训练吞吐量、服务延迟和内存的严格限制,常常限制了在线广告排名模型的复杂性和输入特征集。在像Meta这样的大型系统中,包含数百个具有不同规格的模型,这种挑战更加放大,为每个模型定制用户表示学习变得不切实际。为了应对这些挑战,我们提出了Scaling User Modeling(SUM),这是一个在Meta的广告排名系统中广泛部署的框架,旨在促进跨数百个广告模型高效且可扩展的在线用户表示共享。SUM利用一些指定的上游用户模型,使用先进的建模技术从大量用户特征中合成用户Embedding。然后,这些Embedding作为输入服务于下游的在线广告排名模型,促进了高效的表示共享。为了适应用户特征的动态性,并确保嵌入的新鲜度,我们设计了SUM在线异步平台(SOAP),这是一个无延迟的在线服务系统,辅以模型新鲜度和嵌入稳定化,使得用户模型可以频繁更新,并在每个用户请求时在线推理用户嵌入。我们分享了SUM框架的实践经验,并通过对综合实验的验证来证明其优越性。迄今为止,SUM已在Meta的数百个广告排名模型中启动,每天处理数千亿的用户请求,带来了显著的在线指标提升和基础设施效率的改善。
1 INTRODUCTION
个性化是现代在线广告的基石,它提高了广告商的回报并增强了用户体验。个性化的核心在于理解用户,这传统上依赖于手工设计的特征和简单的架构。基于深度学习的推荐系统的出现改变了这一范式,利用复杂的神经网络模型来学习复杂的用户表示。然而,实际的限制,如训练吞吐量、服务延迟和主机内存,限制了它们充分利用大量用户数据的能力。在像Meta这样的大型系统中,包含许多处理数千亿用户请求的不同模型,这些限制变得更加明显,导致了有效用户表示学习的几个相互关联的挑战:
- 次优表示:独立学习用户表示的模型通常会产生较差的结果。
- 特征冗余:跨模型的用户特征重叠需要在训练流程中进行不必要的复制,导致存储开销高。
- 特定模型的数据稀缺性:服务于细分市场模型缺乏强大的用户理解所需的大量训练数据。
- 密集定制:为每个模型的特定性能需求定制架构和特征选择是不切实际的。
解决这些挑战对于支持用户建模的增长复杂性以及在众多模型中有效扩展表示学习进展至关重要。为了解决这些挑战,我们介绍了用户建模扩展(SUM),这是一个在Meta广告中革命性的在线框架。SUM旨在利用先进的建模技术,同时遵守实际限制,并促进跨模型的高效、可扩展的表示共享。
SUM采用了上游-下游范式(见图1),从最近在用户历史建模方面的工作中汲取灵感。我们的方法包括训练少量大规模的上游用户模型,这些模型在诸如点击和转化等多样化的监督下具有复杂的架构。用户模型处理大量用户信号(特征),以合成紧凑的用户嵌入(表示)。然后,这些嵌入被无缝集成到各种下游生产模型中,传播先进的用户建模和表示共享。
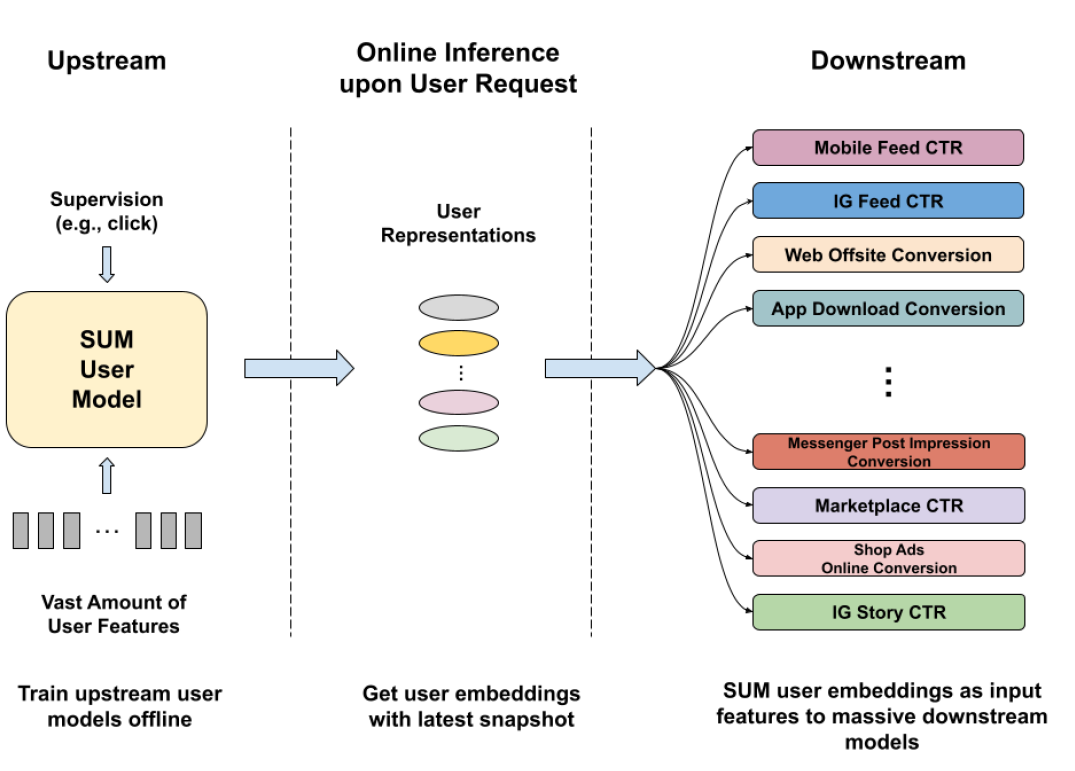
SUM的一个关键设计是其适应用户特征的动态性。我们的服务系统,SUM在线异步平台(SOAP),是一个关键组件,它实现了无延迟的异步服务,实现了嵌入的新鲜度,同时克服了模型复杂性无关的延迟限制,大大超过了传统的基于离线解决方案。SOAP的补充,我们设计了一个循环训练机制,通过平均池化技术增强,以保持模型的新鲜度和稳定用户嵌入。
自最初部署以来,SUM已经在Meta的数百个生产广告排名模型中启动,无论是在离线还是在线业务指标上都取得了显著的改进。它的有效性和适应性也促使其扩展到Meta的Feed和质量模型中。本文的主要贡献包括:
- 我们提出了SUM,一个在线用户建模框架,专注于在生产约束内最优地使用所有现有用户特征和复杂模型,并在数百个模型中扩展表示学习。
- 我们详细描述了一个大规模用户模型架构,这对于从大量输入用户特征中学习有意义的用户表示至关重要,它作为SUM模型的骨干。
- 我们介绍了SOAP,一个无延迟在线服务系统的设计,它平衡了特征新鲜度和服务于约束,超过了离线解决方案并增强了可扩展性。
- 我们提供了广泛的实验研究和从部署SUM中获得的实践见解,包括像平均池化这样的策略,以缓解频繁模型更新导致的嵌入分布转移。
2 RELATED WORK
个性化一直是广告排名和推荐系统研究的前沿。已经提出了大量建模技术来为用户提供定制化的广告。因子化机器(Factorization Machines)使用矩阵分解将高维和稀疏特征转换为低维向量。协同过滤(Collaborative Filtering)利用相似用户和项目的模式来预测用户的个性化推荐。深度学习的普及使现代广告排名模型和推荐系统能够从大规模数据集中学习高阶和非线性交叉。尖端模型如循环神经网络(RNNs)、Transformers和图神经网络(GNNs)进一步推进了个性化的深度和广度。
尽管如此,严格的基础设施限制常常限制了在线模型中模型架构的复杂性和用户特征的范围,阻碍了最优用户表示。因此,业界采纳了基于Embedding的方法,利用上游-下游范式。上游模型通常在线下训练和更新,以产生浓缩的Embedding,这些Embedding将用作下游在线生产模型的输入特征。这样,放宽了延迟限制,允许更大的模型复杂性。Embedding主要包含item Embedding和user embedding。
对于item Embedding,Twitter的TwHin从异构知识图中派生Embedding,捕捉用户、推文和广告的细微差别。Pinterest的PinSage结合了随机游走和图卷积来学习图节点Embedding。Airbnb提取lists embedding以改善搜索排名,这些embedding是离线预计算的,并每天存储,以使它们在在线服务期间实时可用。ItemSage利用基于Transformer的架构从多模态中学习item embedding,这在计算上是昂贵的。它采用了一种离线服务解决方案,每天进行批量推理。鉴于项目特征的固有稳定性,这种离线服务解决方案中的嵌入陈旧仍然是可以接受的。但对于SUM使用的用户特征,它显著地影响了user embedding性能,正如后面部分所讨论的,这使得确保embedding的新鲜度对于SUM的生产化至关重要。
对于user embedding,Pinterest的PinnerFormer对用户序列进行建模,依赖于每天的线下批量设置来减少基础设施压力。腾讯学习用户应用使用Embedding,并每天为活跃用户更新它们,而上游模型更新则不太频繁,以避免嵌入分布转移和相应的下游模型更新。阿里通过端到端学习挖掘长期用户行为,这将用户建模部分从整个模型中解耦,并存储最新的user embedding以便于在线访问。user embedding更新是由用户行为事件触发的,而不是流量请求。以前的研究主要集中在学习用户历史行为上,同时还需要额外的努力来构建和维护以用户为中心的行为数据管道。而这项工作专注于探索一种可行的解决方案,以支持用户建模的日益增长的复杂性,这些复杂性在生产广告模型中直接添加是不切实际的,并且在大规模广告排名系统中有效地扩展用户表示共享。
3 MODEL ARCHITECTURE
3.1 Preliminary
如图2所示,SUM用户模型采用了著名的DLRM架构。它分为两个主要部分:用户塔(user tower)和混合塔(mixed tower)。用户塔处理广泛的用户侧输入特征,将它们转换成一组精炼的SUM user embedding。然后,这些embeddings被传递到混合塔,在那里它们与其他类型的特征(如与广告相关的特性)进行进一步的交叉。
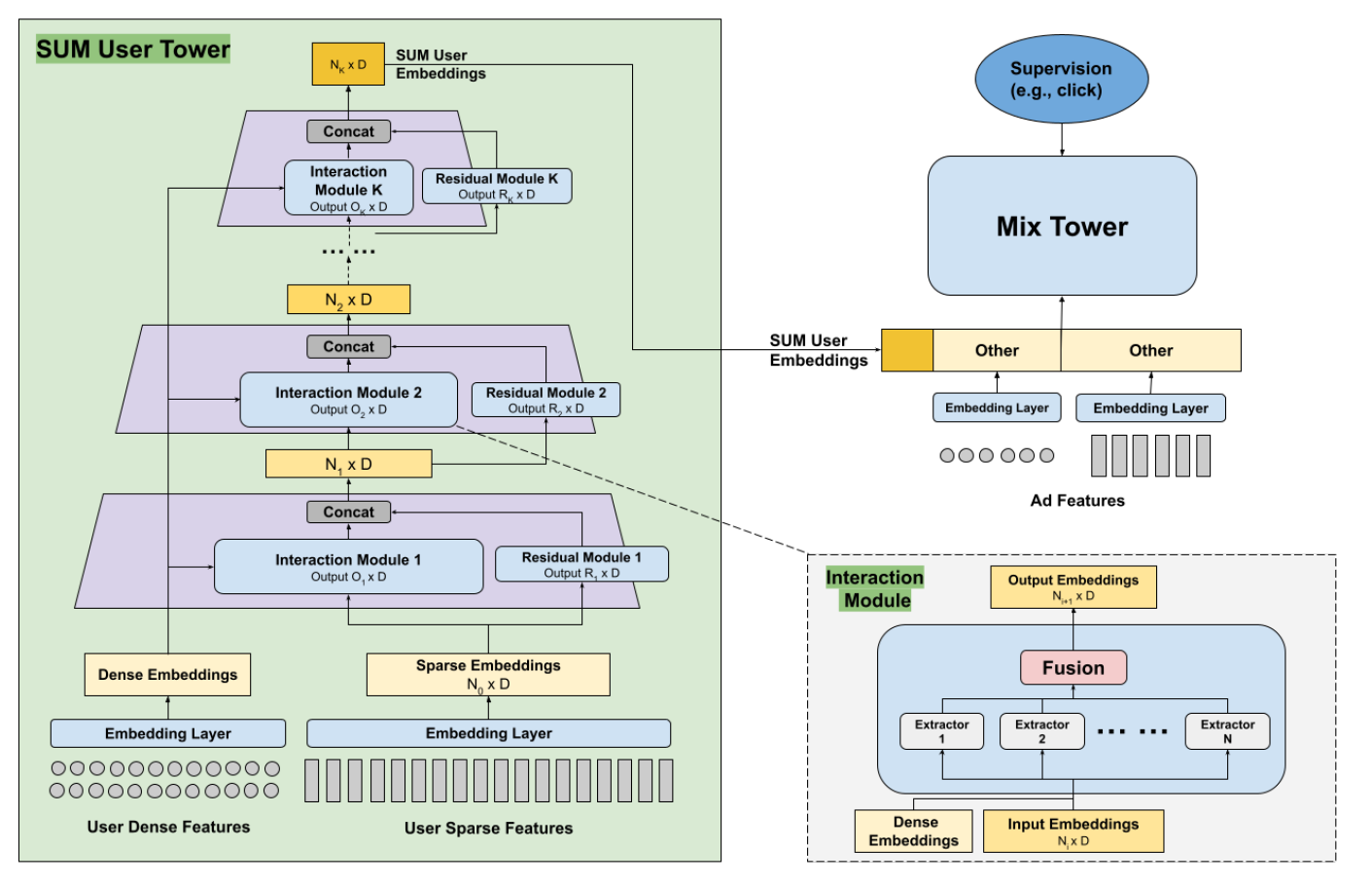
我们将输入用户特征分为两大类:密集特征(dense)和稀疏特征(sparse)。密集特征是数值型或连续变量,例如特定页面的点击频率。稀疏特征通常是具有高基数的分类或二元变量,包括用户ID和页面ID。这些稀疏特征对存储和计算要求较高,需要Embedding查找表来将原始值映射到密集Embedding,这需要非常大的参数数量。标准模型通常处理不到300个用户稀疏特征,而更紧凑的模型则限制在100个以下。相比之下,SUM用户模型则要广泛得多,能够容纳更多的用户特征,远远超过下游模型所管理的特征数量。
3.2 User Tower
用户塔采用了金字塔式的结构,通过连续的交叉模块(Interaction Modules)有系统地压缩这些输入特征。应用了残差连接以便于训练并保留原始信息。Dense特征和Sparse特征经过初始Embedding层后,我们有$D$维的$N_0$个Sparse Embedding和$N_{dense}$个Dense Embedding,用户塔将它们合并成$N_K$个相同维度user embeddings输出,其中$N_0 » N_K$. 对于第n个交叉模块,
\[X_n = Concat(Interaction(X_{n-1}, X_{dense}), Residual(X_{n-1}))\]其中,Interaction和Residual分别表示图2中的交叉模块和残差模块.$X_{n-1}$是第n个交叉模块的输入,$X_{dense} \in R^{N_{dense} \times D}$初始Embedding层后的原始embedding。残差模块通常是多层感知机(MLP)。交叉模块集成了多个并行的特征提取器,旨在捕捉一系列互补的交叉。特征提取器有多种选项,以下是其中的一些:
- MLP:它用于学习一般的非线性低级隐式表示。
- 带注意力的点压缩(Dot Compression with Attention):压缩成对点积矩阵是提高模型容量和效率的有效方法.我们结合了高级点压缩、注意力和残差连接来学习高级显式表示,公式如下:
其中,$FC(*)$表示非线性函数的全连接层,$LC(*)$表示线性压缩,对于Dense特征,$LC(X_{dense}) = FC(X_{dense})$。对于Sparse特征来说,$LC(X)$是$X$所对应的embeding的加权和。我们在$Concat(*)$之前使用$LC(*)$的原因是为了减少$MLP(*)$的输入尺寸,以提高模型效率,$Y$是注意力权重,$Z$是Residual分支
- 深度交叉网络(Deep Cross Net,DCN):通过有效的显式和隐式特征交叉学习表达性表示。其基本组件是交叉层,可以通过以下方程式说明
其中$W_n$和$b_n$是可学习的权重和偏差。通过堆叠多个交叉层,模型可以捕捉到高阶的向量级和位级交叉。
- MLP-Mixer:是一种全MLP架构,最初是为计算机视觉设计的。这种架构可以被视为一种独特的CNN,它使用$1 \times 1$的卷积进行通道混合,以及单通道深度卷积进行标记混合,如方程如下所示:
其中$W_1, W_2, W_3, W_4$是可学习的权重
3.3 Mix Tower
混合塔(Mix Tower)采用了DHEN风格的架构。除了来自用户塔的SUM用户嵌入外,它不包含任何用户侧特征作为输入。这种战略性的设计选择旨在增强上游训练吞吐量,并鼓励模型主要通过用户塔来提炼用户表示。我们的经验表明,尽管更复杂的混合塔架构显示出更强大的上游模型预测性能,但它并没有显著提高用户嵌入的质量或带来下游的好处。我们使用多任务交叉熵损失:
\[\zeta = -\frac{1}{N} \sum_{i=1}^{N} \sum_{t=1}^{T} w_t (y_{t_i} log(\overline y_{t_i}) + (1 - y_{t_i}) log(1 - \overline y_{t_i}))\]其中$w_t$是任务$t (t=1, 2, \cdots, T)$的权重,代表其在最终损失中的重要性,$y_{t_i} \in {0, 1}$是任务$t$中的第$i$个样本的label,$\overline y_{t_i}$是任务$t$中的第$i$个样本的预测值,$N$是样本的数量。
4 ONLINE SERVING SYSTEM: SOAP
与其他论文中使用的相对稳定的商品特征不同,SUM用户塔中用户特征经常发生剧烈变化。这些特征中有相当一部分是分类变量,这些变量面临着新ID引入和现有ID语义变化的挑战。在这种情况下,基于离线的服务体系提供的Embedding,无论是批量推理还是事件触发推理,都可能对下游性能产生不利影响。因此,我们决定对每个用户请求在线推理用户Embedding。然而,在线推理的延迟预算通常很紧张。通常,一旦收到用户请求,只有30毫秒的窗口时间来进行推理并将用户嵌入传递给下游排名模型,从而限制了用户模型的复杂性,进而限制了SUM用户嵌入的代表性。
为了应对上述挑战,我们设计了SUM在线异步平台(SOAP),它利用了为SUM在线推理量身定制的新颖异步服务体系。如图3所示,
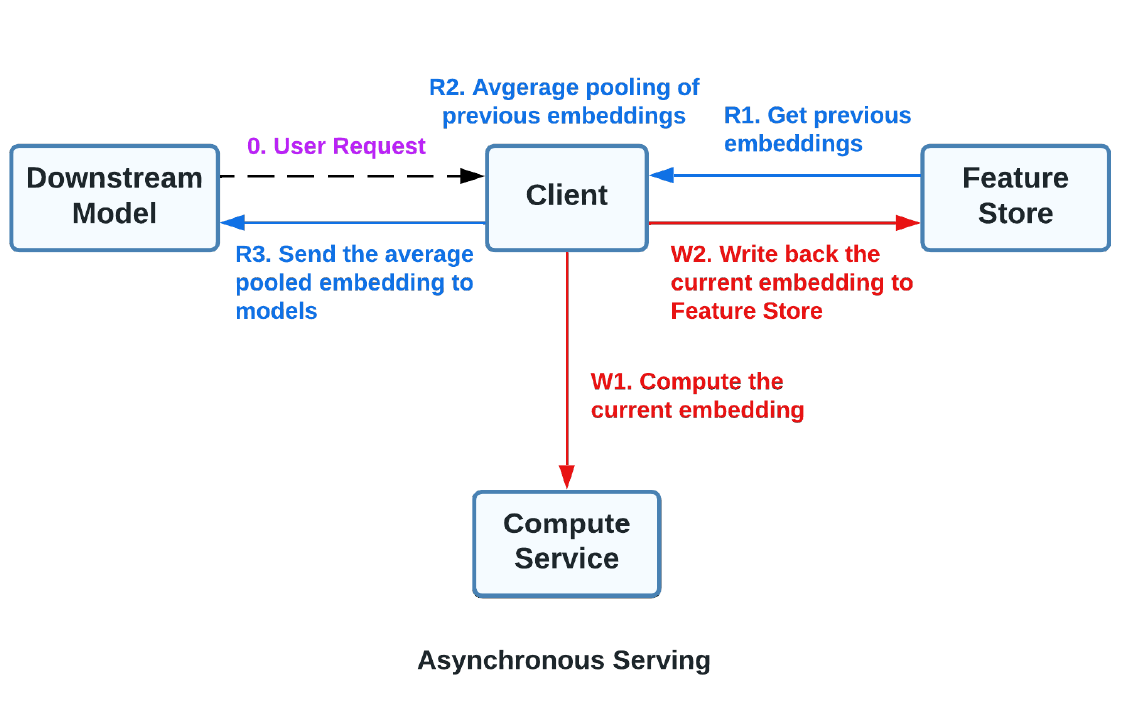
当下游模型收到用户请求时,SOAP计算中心使用最新快照计算当前嵌入,然后将其写入特征存储。同时,客户端立即从特征存储中读取该用户的先前嵌入,并将平均池化embedding转发给下游模型,而不需要等待计算中心的推理结束。通过这种方式,SOAP将特征写入路径与读取路径解耦。当前embedding的计算和更新被调用为异步调用。通过将昂贵且耗时的写入路径与读取路径分离,异步服务有效地消除了延迟限制,理论上可以支持具有任意长推理延迟的复杂用户模型(实际上,推理延迟仍将成比例地影响服务功率使用,但它不再是一个硬性阻碍)。它显著优于基于离线的方法,同时牺牲了一定程度的实时性以提高扩展潜力,从而提高了ROI。
为了进一步减少推理时间,SOAP中仅提供SUM用户模型的用户塔来生成用户嵌入,而不是整个模型。
5 PRODUCTIONIZATION
5.1 Model Training
SUM用户模型以增量方式离线训练,这允许模型在适应不断变化的用户偏好的同时保留历史模式。这种频繁的快照发布,结合在线推理,使SUM能够持续地向下游模型提供最新的uer embedding
5.2 Embedding Distribution Shift
然而,随着增量训练的进行,用户模型不断发布新的快照。这意味着即使对于相同的推理输入,计算出的用户嵌入也会随着时间变化。我们称这种现象为“嵌入分布偏移”。它显著损害了用户嵌入的有效性。有两种选择可以缓解嵌入分布偏移
- Option 1: 确保在推理中使用之前,下游模型在训练期间已经看到嵌入特征的新版本。这个选项需要在模型训练、服务和特征日志记录方面进行更改,这为我们的系统带来了额外的复杂性
- Option 2: 通过强制新版本与先前版本相似来减少分布偏移。这可以通过正则化、蒸馏和平均池化等不同的方式实现。
我们建议通过平均池化对2个最近的缓存embedding和当前计算的embedding进行平均池化,作为该用户的最终当前embedding。平均池化在广告排名和推荐系统中被广泛采用,特别是为了应对代码启动问题。我们选择这个选项是因为它成本低,性能好,并免费增加特征覆盖率
5.3 Feature Storage Optimization
在生产中,我们通常配置K=2和D=96,这意味着用户模型生成2个SUM用户嵌入,每个嵌入的维度为96。在调查了K值之后,我们发现K=2在性能提升和特征存储效率之间有良好的ROI。为了进一步减少在线和离线存储使用,两个用户嵌入从fp32量化为fp16;我们评估过这种量化不会导致下游表现效果差异
5.4 Distributed Inference
为了解除SUM用户模型的内存限制以获得更多的性能提升,我们为用户塔结合了分布式推理(DI),以便在线推理工作负载可以在多个主机之间有效分配。
6 EXPERIMENTS
6.1 Experimental Setup
6.1.1 Dataset
在这项工作中,所有实验都在工业数据集上进行。我们没有使用公共数据集,因为将它们应用到我们的服务体系上存在差距,与内部模型的较大差异使它们不适合下游实验。
6.1.2 Evaluation Metric
标准化熵(Normalized Entropy)使用标准化熵(NE)定义如下,作为评估模型预测性能的指标。它衡量模型预测用户点击广告的准确性。它相当于每次展示的平均对数损失除以如果模型预测背景点击率(CTR,即总是预测平均CTR的恒定模型)的每次展示的平均对数损失,越低越好。
\[NE = \frac{-\frac{1}{N} \sum_{i=1}^{N} (y_i log p_i + (1-y_i) log (1 - p_i))}{- (p log p + (1-p) log (1 - p))}\]其中$N$表示数据集中的样本数,$y_i \in {0, 1} $ $i = 1, 2, \cdots, N$是label, $p_i$每次展示的点击估计概率, $p$是平均经验值
特征重要性排名(Feature Importance Ranking)。我们使用特征重要性排名(FI)[1]来评估一个特征对模型的重要性。用户模型生成的SUM嵌入被送入各种生产模型作为输入。通过分析SUM嵌入与其他可用特征的FI排名,我们可以了解SUM用户嵌入的相对价值和影响。
6.1.3 FB CTR SUM User Model
在实践中,我们维护一些SUM用户模型,每个模型都训练在不同的数据集和监督上。作为我们接下来讨论的代表性例子,我们将关注FB CTR SUM用户模型。FB CTR SUM用户模型利用Facebook移动应用源的数据集,包含大约60亿个日常示例,并针对CTR预测任务。用户塔由四个顺序堆叠的交叉模块组成,采用MLP、带注意力的点压缩和MLPMixer作为特征提取器。它处理了大约600个用户侧稀疏特征和1000个用户侧密集特征。结果,用户塔占用了160 GB的体积,需要390M推理FLOPs
6.2 Downstream Offline Results
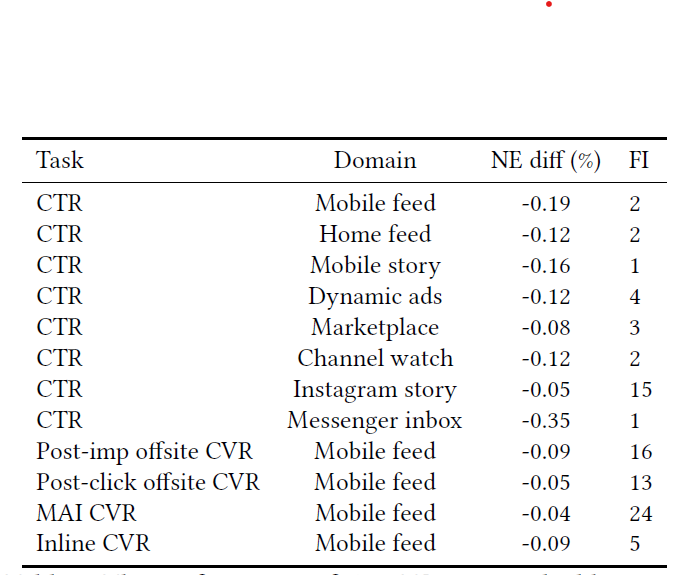
表1列出了FB CTR SUM在一些下游模型上的离线NE性能。从表1中,我们可以看到SUM嵌入在CTR预测、内联转化预测、移动应用安装转化预测和各种领域的离线转化预测等多种下游任务中带来了统计上显著的NE增益

这一结果强调了SUM的强大代表性和泛化能力。预计它们在CTR任务中会显示出更高的增益,因为它们是在CTR数据上训练的。一个特殊情况是,在Instagram模型上的增益相对较小,这突出了需要一个Instagram SUM模型来弥合FB和Instagram之间的领域差异。此外,在像Messenger收件箱这样的小型模型上,模型复杂度和特征数量较低,从大规模用户表示共享中获得的好处更加明显。值得注意的是,添加SUM嵌入对下游模型的训练吞吐量或其他基础设施指标的改变很小,因为嵌入特征是密集表示,不需要计算密集型的嵌入查找表,这些查找表对于稀疏特征是必需的。
6.3 Online Performance
SUM已经在Meta的数百个生产广告模型中启动,无论是在离线还是在线业务指标上都取得了显著的增益,惠及了IG、FAM、Shop Ads、Messenger Ads等多个平台。在线A/B测试表明,SUM总共带来了2.67%的在线广告指标增益(0.2%的增益在内部可以认为是统计学上显著的)。值得注意的是,在实现这些增益的同时,与直接将相同复杂性引入每个下游模型相比,SUM成功避免了15.3%的服务能力增加
6.4 Async Serving
我们进行了实验,比较了4种不同的服务解决方案。
- 冻结用户模型:用户模型只训练一次,我们不断使用初始快照来评估新数据并生成用户嵌入。这种设置要有效,一个重要的先决条件是只使用稳定的基于内容的特征作为输入,而不是短命的ID特征,这在很大程度上限制了输入特征空间。鉴于我们当前用户模型的设置试图利用所有现有的用户端信息,而不区分稳定特征和非稳定特征,冻结模型设置可能无法充分发挥用户模型的潜力。
- 离线批处理:用户模型在初始训练完成后每天都会进行循环训练。我们使用(ds-1)上训练的快照来评估(ds)上的数据,以产生用户嵌入。通常情况下,通常会有1到3天的陈旧性,这取决于下游模型的数据管道设计。
- 在线实时服务:在收到用户请求后,客户端从计算服务中获取当前嵌入,并从Feature Store获取之前的嵌入,然后将平均池化的嵌入作为最终当前嵌入转发到下游模型。如果计算服务的推理没有在规定的延迟窗口内完成,则被视为回落。
- 在线异步服务: 详情见第4节。
为了公平比较实时服务和异步服务,我们在这组实验中使用的用户模型是一个更紧凑的版本,只有20M推理FLOPs,因为更大的模型会有非常高的回落率。结果如表2所示,从实时模型服务过渡到异步服务只会造成平均10%的损失,这比从实时服务过渡到离线批处理设置时观察到的损失要小得多。此外,它为使用更复杂的用户模型铺平了道路,强调了异步服务的好处。
6.5 Embedding Distribution Shift
我们进行了离线实验,以了解嵌入分布偏移问题。这里SUM用户模型处于离线批处理模式,以便于进行端到端实验,即我们每天都会对用户模型进行循环训练,并使用每天更新的移动快照转储user embedding。两个user embeddings分别表示为$Embedding0$和$Embedding1$,对于每个用户,我们比较连续日期上嵌入的余弦相似性和L2范数变化,并在表3中报告平均值。一个旁注是,我们还发现$Embedding1$比$Embedding0$为下游模型带来了更大的训练NE增益,但$Embedding0$在$Embedding1$之上可以带来额外的增益。为什么一个嵌入比另一个更稳定,以及为什么更稳定的嵌入会带来更大的训练增益,这不是这项工作的重点。它可以是未来改进的潜在领域。如表4所示,没有平均池化,可以观察到良好的训练NE增益,这意味着在训练期间下游模型可以适应嵌入分布偏移。然而,评估NE增益要小得多,这是意料之中的:对于评估,嵌入特征是由一个新的用户模型快照生成的,新版本的嵌入在训练期间没有被下游模型看到。突然的变化导致更差的评估NE。
平均池化3个嵌入可以显著减少嵌入偏移,并提高性能,特别是在评估NE方面。
7 CONCLUSION
在本文中,我们介绍了SUM,这是一个大规模在线个性化框架,它利用少数SUM用户模型综合的用户表示,为Meta的广告排名模型提供支持。我们创新的SOAP服务系统促进了SUM用户嵌入的在线异步推理,并辅以用户模型的新鲜度和嵌入的稳定性,这不仅提高了与离线服务方法相比的嵌入的新鲜度,还解锁了更复杂的用户模型的潜力。我们深入探讨了部署SUM的挑战和最佳实践。实验结果,加上它在Meta内部的成功推出,证明了SUM的优越性。SUM已经在Meta的数百个生产广告模型中启动,每天处理数千亿用户请求。我们相信,这项工作提供了一种实用、可扩展和高效的方法,通过有效的用户嵌入共享来改进广告个性化,并解决在线广告模型在训练吞吐量、内存和服务能力方面的固有限制。展望未来,我们渴望进一步完善用户建模算法和服务系统,以实现更细腻的用户表示。